
I used to co-host a podcast called The Downtime Project. Each episode, my old friend Tom Kleinpeter and I walked through a public tech postmortem, extracted lessons, and related our own stories about outages of our past projects. Back then, in 2021, Convex was just a prototype. Once or twice, I commented on air that karma would ensure Convex got its own Downtime Project-worthy incident or two one day. Here we are! Let's dive in.
First, I want to apologize to all the T3 Chat users who were impacted by Sunday's outage. Despite what Theo's discount code might lead you to believe, none of this was Theo's fault. It was Convex's fault.
The vast majority of Convex is open source, so throughout this post, I'll refer to our public source code and PRs whenever I can.
This is a complex outage, so bear with me! I hope to tie it all together in the end.
Outage Context
Generally speaking, T3 Chat’s traffic should be manageable by Convex, even at a 10x or 100x higher level. But there are two things about T3 Chat's use of Convex that are new for us, and led to system states we were underprepared for:
- T3 Chat relies more heavily on text search than other high-traffic Convex customers.
- Users frequently leave T3 Chat open in a background tab, so it's there when they need it.
These two factors combined led to a new operational pattern on our platform that set the stage for Sunday's outage.
And perhaps a bit of background on Convex is helpful to cover as well:
- Convex manages its sync protocol over a WebSocket.
- Convex is a reactive backend. Clients can subscribe to TypeScript server "query functions." When mutation functions change some records in the database, Convex ensures the affected subscriptions are updated by re-running the queries and producing the new results. We call that "query invalidation."
- As we've scaled up customers, we've slowly accumulated a vast list of knobs. These are runtime-customizable parameters that we can adjust on a case-by-case basis to make larger customers scale smoothly. They represent resources, cache sizes, limits, etc, within a Convex deployment.
- Convex's text search system is much less proven to be performant at scale than the rest of our platform. There are performance bottlenecks we're now just tuning for T3 Chat.
Impact
T3 Chat was slow for various periods between 6:30a PT and approximately 9:45a PT.
T3 Chat was essentially unusable between 9:45a and 12:27p.
Outage Timeline
What we did and what we knew, in real time. All times are PT on Sunday, June 1, 2025.
6-7a: The Convex on-call engineer noticed elevated error rates for some T3 Chat users. The errors subsided, and load returned to normal, so the investigation was tabled until more engineers were online.
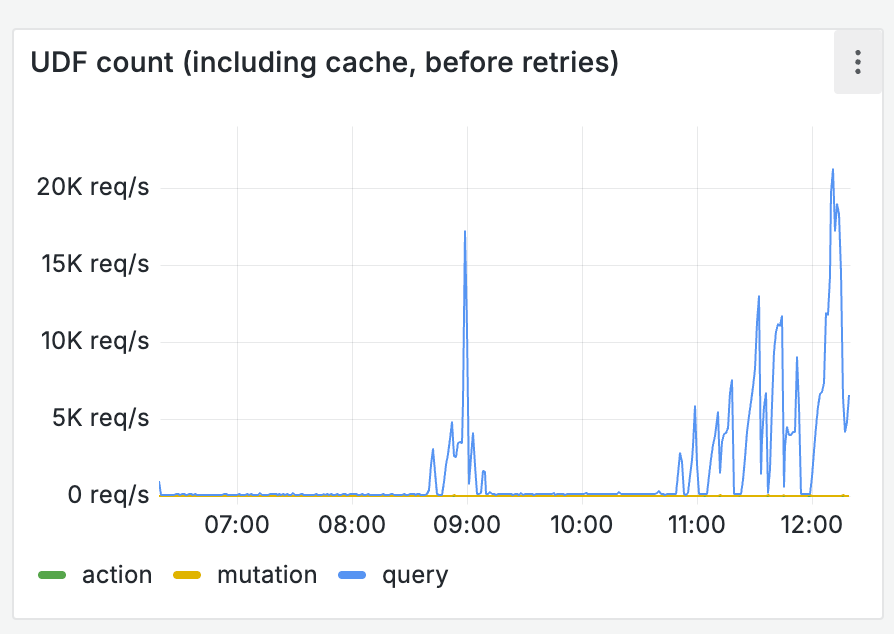
~9:30a: The errors returned. With several engineers online, the team realized a new limit within the codebase was being hit as more T3 Chat users were waking up and using the app: the number of pending subscriptions that needed to be refreshed. T3 Chat was periodically having giant spikes of query invalidations and server function runs. With more users online, those jobs were starting to overflow a queue of waiting queries during the spikes, which caused the server to drop WebSocket connections. We didn't yet understand why T3 chat was sporadically going from a steady-state query load of ~50 queries per second to 20,000+ per second (Problem #1. more on that later). But our first instinct was to turn this hard-coded queue size limit into a knob so we didn't cause all the clients to crash and reconnect. That would buy us time to investigate.
10:01a: We turned this queue into a knob with a plan to redeploy the binary and increase this limit from 10,000 to 100,000 for T3 Chat: https://github.com/get-convex/convex-backend/commit/da0dc1e3f57cddd81a5f43d13f614408c65a95bd
~10:15a: While simulating the failure T3 Chat was having, our engineering team noticed that the Convex client didn't back off when this particular failure occurred. Problem #2: The client would immediately reconnect and slam the server with all the same queries that caused the issue in the first place. We realized the current logic about backing off to shed load from an overloaded server was deeply flawed. We submitted this change to the Convex client to prevent the thundering herd: https://github.com/get-convex/convex-js/commit/439a8e387e9e530270316cdc9d7dcb8d15d00338
~10:15a+: The T3 Chat team pushed a version of their site with the new Convex client build that backed off better and used modals in the app to encourage online users to refresh their browsers. Unfortunately, most of the load came from background tabs, and there was no mechanism to force a refresh. So the old Convex client code kept hammering the backend, overflowing the queue, disconnecting, and reconnecting.
10:48a: The new backend binary passed all tests, and so was pushed to T3 Chat's Convex deployment so we could increase the knob to allow for a longer queue. (Problem #3, unbeknownst to us; more on that later!)
11a-12p: The thundering herd continued to just overwhelm the T3 Chat Convex deployment. We honestly could not figure out what was happening. We profiled the app and found several optimization opportunities to speed up the Convex engine. But even though each one made things run a little faster, and T3 Chat almost fully recovered despite the thundering herd, it never returned to equilibrium. In desperation, we prepared to block ranges of IPs at the traffic level to allow all the clients to finish syncing, forcing a kind of backoff + jitter.
12:04p: An engineer on our team noticed that while we were manually pushing out fixes to T3's Chat's Convex deployment during the outage, we accidentally had placed the deployment back onto the "default" hardware resources used by free accounts. 😔 We debated fixing this immediately, but it felt like the weaker hardware had almost gotten the site back online. So we delayed fixing the issue a few more minutes to see if we could get everyone in sync before restarting the backend again.
12:26p: Still unhappy with the recovery progress, we made the call to redeploy yet again onto the appropriate, more powerful hardware resources.
12:27p: T3 Chat was fully recovered.
Root Cause Analysis
Now that we've done everything in chronological order, with the benefit of hindsight, let's organize what really happened here into the core issues:
Problem #1: Search indexing compaction causing query invalidation
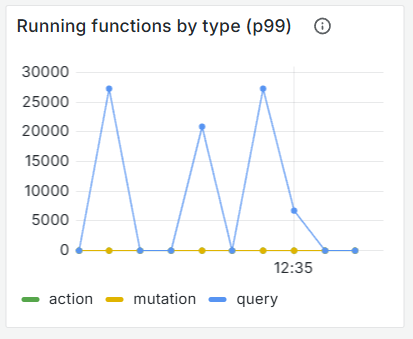
Why was T3 Chat going from a few dozen queries per second to 10s of thousands in an instant, overflowing the queues and starting the DDOS?
First, we did what came naturally: accuse the customer, of course!
And it ends up it's our fault.
It turns out that when our search indexing service runs a compaction, it causes any documents with search-indexed fields currently in a subscription to be invalidated, even though no real data has been changed.
For T3 Chat, every online user is subscribed to the first 20 messages for preloading. So thousands of clients would recalculate tens of thousands of queries as fast as possible when our background compaction would run... which happened a few times an hour.
Convex is actually really fast, so we didn't even notice this. Until the number of queries overshot the queue size and caused clients to get into retry loops.
Problem #2: The Convex client's backoff logic was insufficiently nuanced
The Convex client does exponential backoff if it's having trouble connecting to a server. However, if it successfully connects, it resets its exponent to zero.
But merely connecting the WebSocket does not mean the server is healthy and ready to serve traffic. Instead, it can connect, issue expensive queries, have an overloaded server drop the connection, and then it will just do the whole thing over again. That's what happened here, resulting in a DDOS from our own clients, since they were all trying to re-run these tens of thousands of invalidated queries when they reconnected to the server.
If they had backed off with jitter, they would have spread those queries across many seconds or minutes. Eventually, T3 Chat would have gotten back into equilibrium, probably even on lesser hardware. Which leads us to...
Problem #3: Operational tooling did not enforce account-specific provisioning rules
The final, most human, and frankly silliest problem ultimately contributed the most to T3 Chat's downtime.
Even with search indexing causing needless traffic spikes and too-simplistic client backoff hammering our platform, Convex would have powered through the work no problem once we had given the backend a bigger query queue. We know because that's exactly what it did at 12:27p.
However, the tool we used to push code manually in our clusters during the outage didn't preserve the provisioned resources appropriate for particular accounts, and we forgot to manually override it when we were hastily trying to fix the system.
We spent more than an hour looking for complicated, architectural reasons T3 Chat was down when the issue was quite simple: the CPU was overloaded because it was running on the wrong type of VM.
Humans are allowed to make mistakes, especially under stress. So, tooling needs to protect them from those mistakes. We haven't built these safeguards into all our operational tooling yet, and we must fix that ASAP.
Follow-Up Action Items
Immediate
- Ensure all tooling honors codified hardware class and resource assignments per deployment.
- Optimize search index compaction to no longer invalidate query sets when no actual indexed data has changed.
- Ship a new Convex client library with more comprehensive backoff behavior.
Soon
- CPU-optimize the subscription engine to store index keys rather than computing them at intersection time.
- Develop new benchmarks and load testers around DDOS and search indexing use cases.
- Add server-side buffering/backoff of Convex sessions to be more robust against adversarial workloads or old clients.
- Add configurable, built-in support for dropping WebSockets for inactive tabs in the Convex client (perhaps falling back to periodic polling).
